
[컴퓨터아키텍처] 5주차 수업 내용 정리
명령 파이프라인
- 도입: 공장의 라인을 생각해 보자
- 콘베이어 벨트 라인 위에 제품이 지나감
- 4명의 사람이 각각 공정 작업을 해 나가며 완성됨
- 제품이 하나밖에 나오지 않는다면 한 사람이 작업할 때 다른 사람들은 한가해짐
- 실제 공장: 여러 제품을 동시에 흐르게 하는 방식
- 각 공정을 병렬로 처리함으로써 처리량을 향상시키는 방식임
- 앞서 설명한 것보다 4배 빠른 속도로 제품이 완성됨
- 이것이 바로 명령 파이프라인 방식임
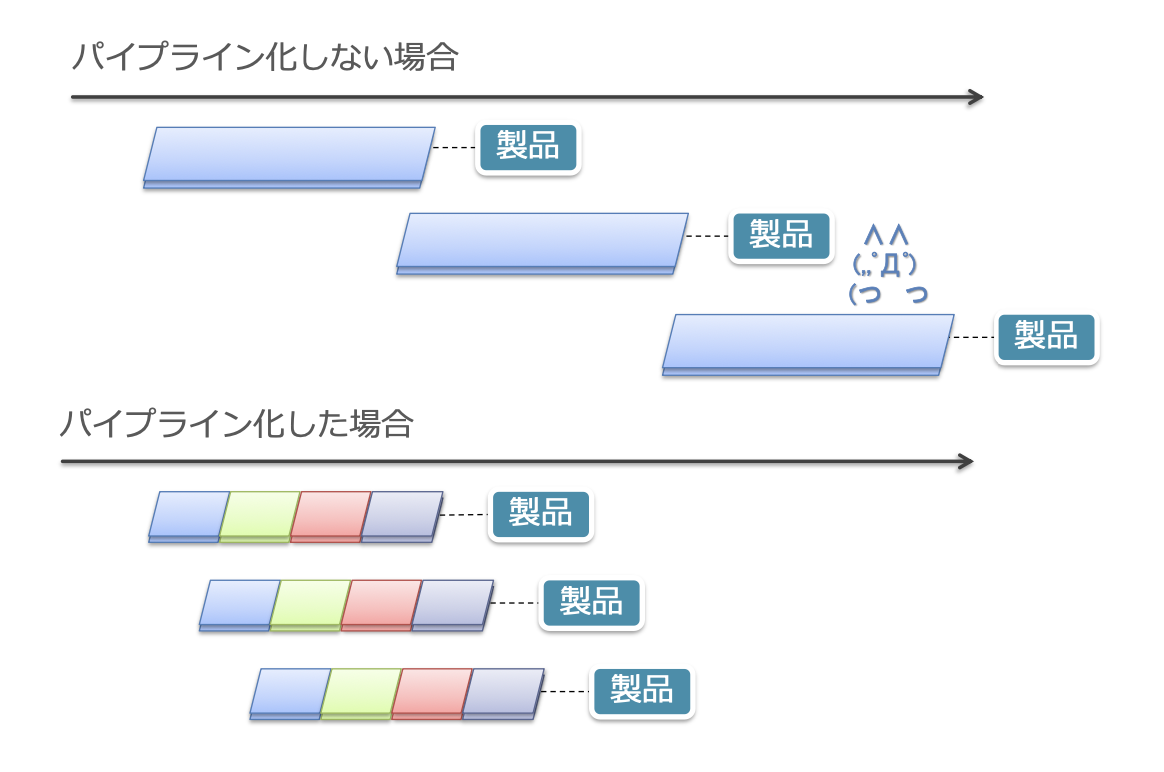
- 콘베이어 벨트 라인 위에 제품이 지나감
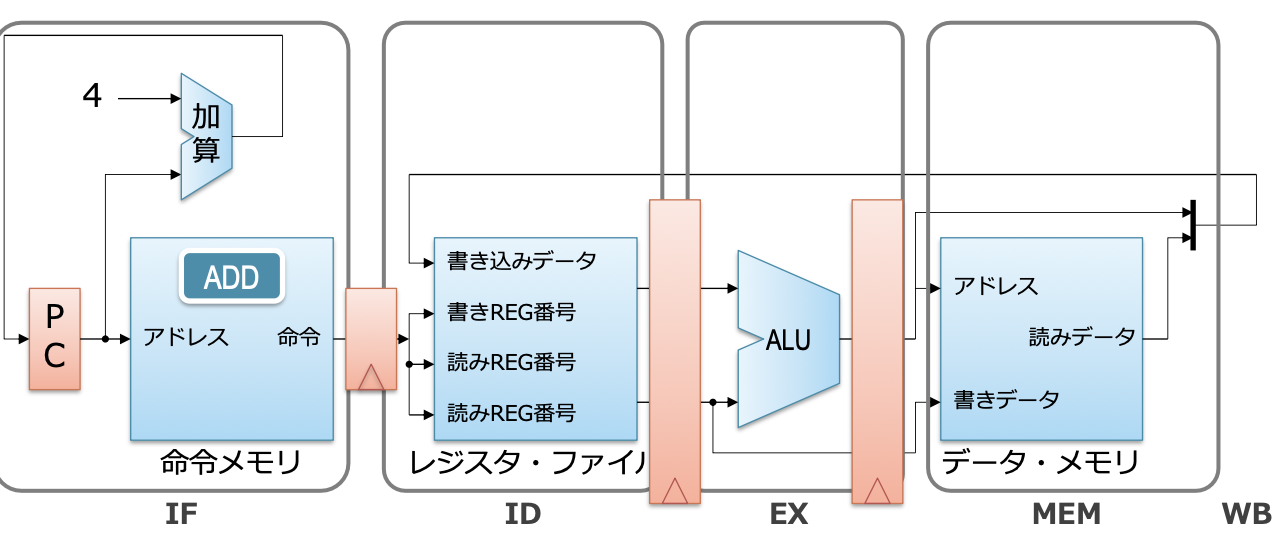
싱글 사이클 프로세서의 동작
- 모든 명령의 처리가 1 사이클 안에 완료되는 방식
- 지금까지 설명했던 프로세서의 동작과 동일한 방식임
- 파이프라인화를 전제로 한, 더 구체적인 구조를 사용하여 복습하는 방식임
지금까지 설명한 CPU의 이미지
- 컴퓨터의 핵심 부품
- 메모리에서 명령을 읽어 계산을 수행하는 역할을 함
- 구성 요소
- 연산기(FU: Functional Unit)
- 가산기나 AND 연산기 등
- 지시된 종류의 연산을 수행
- 레지스터 파일 (오른쪽 그림에서는 A, B, C…)
- 메모리처럼 데이터를 저장하는 역할
- 위치를 지정하여 읽기와 쓰기를 수행함
- CPU의 연산은 이 레지스터 상에서만 수행됨
- PC (Program Counter)
- 현재 보고 있는 명령의 주소를 기억하는 장소
- 연산기(FU: Functional Unit)
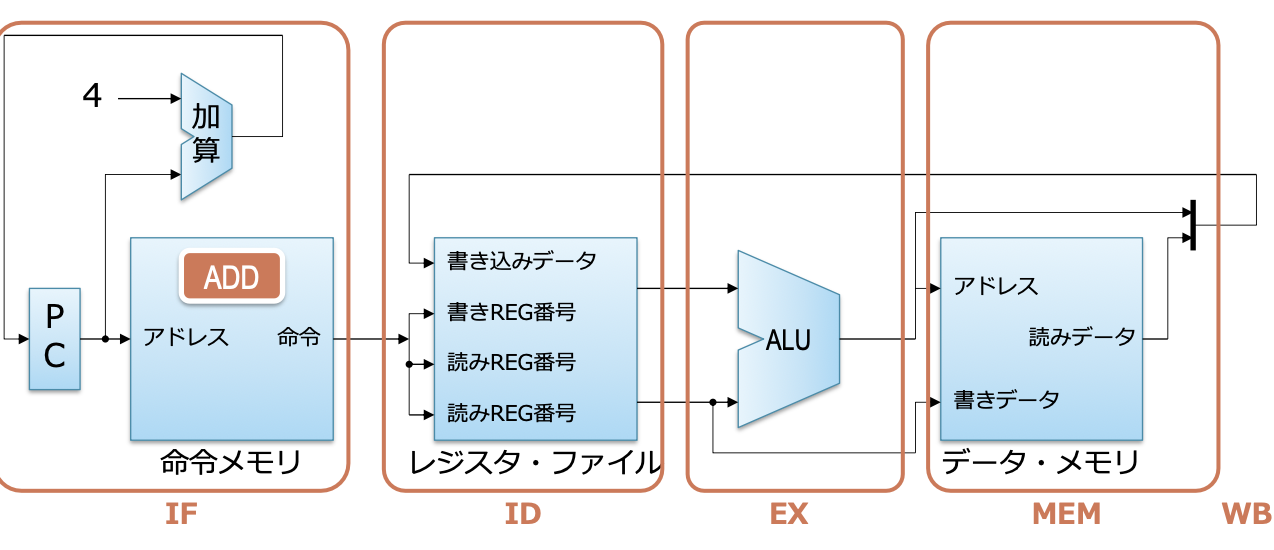
베이스가 되는 싱글 사이클 프로세서
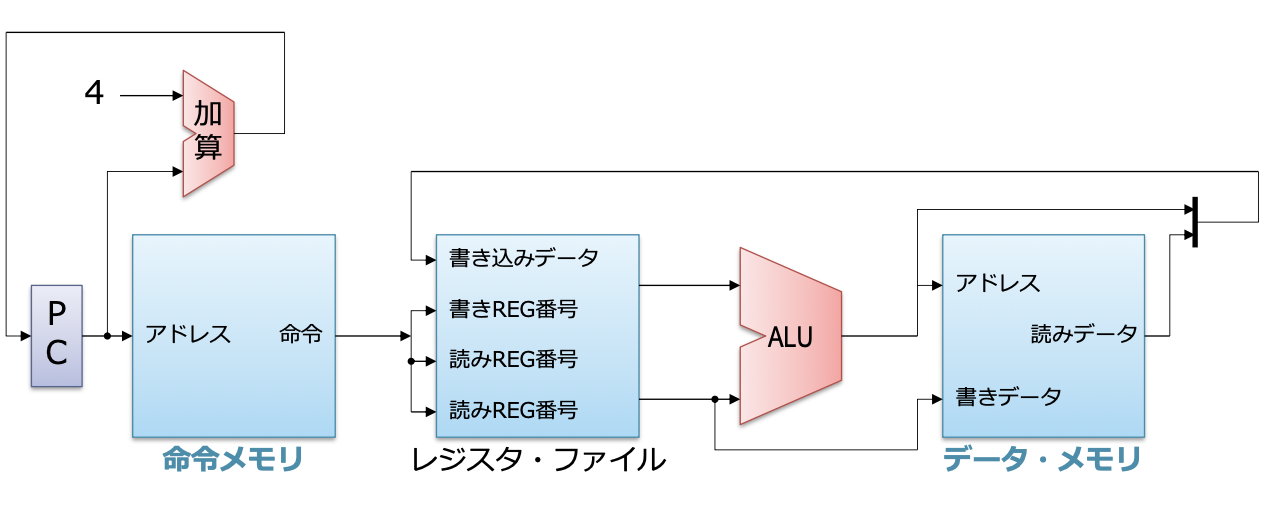
- 이전에 설명했던 것과의 차이점
- 메모리가 명령 메모리와 데이터 메모리로 나뉘어 있음
- 산술 및 논리 연산, 로드, 스토어만 실행 가능함
- 분기와 점프는 간단히 하기 위해 지금은 고려하지 않음
- 명령 하나의 실행 페이즈
- 패치 フェッチ
- 디코드 デコード
- 레지스터 읽어 오기
- 실행
- 레지스터에 써 넣기
-
RISC-V의 덧셈 명령을 실행하는 흐름
-
명령 패치
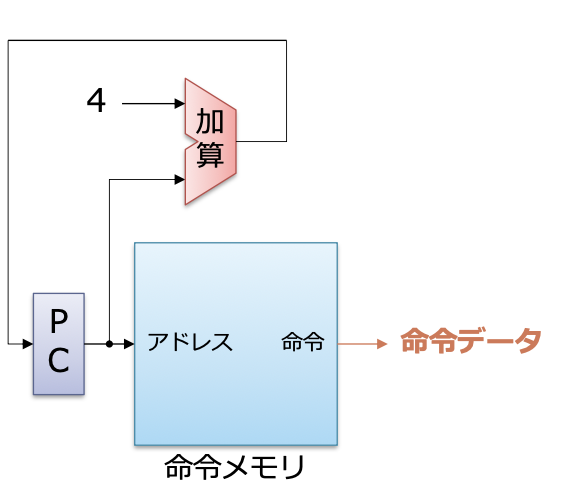
- 명령 메모리에서 명령을 읽어오는 방식
- 명령 메모리를 순서대로 읽기 위해, PC는 매 사이클마다 증가함
- 더해지는 4는, RISC-V에서 명령어의 크기가 4바이트이기 때문임
- 기본적으로 이 부분은 어떤 명령에서도 변하지 않는 부분임
- 명령 메모리에서 명령을 읽어오는 방식
-
명령 디코드
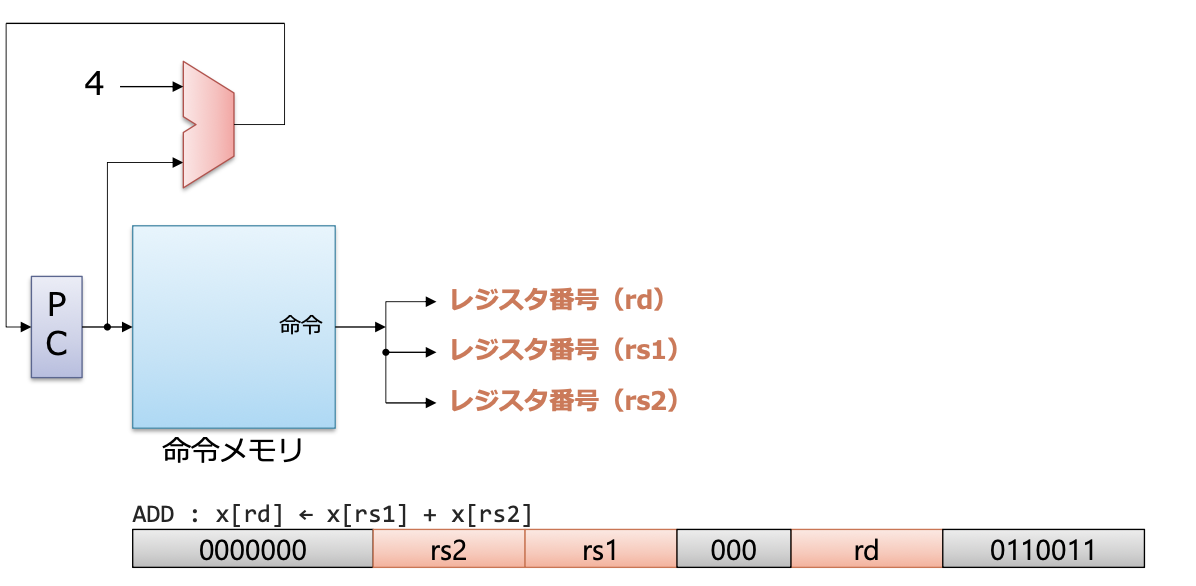
- 받은 명령으로부터 레지스터 번호를 나타내는 부분의 비트를 읽어 옴
- 소스
rs1,rs2와 데스티네이션rd
- 소스
- 받은 명령으로부터 레지스터 번호를 나타내는 부분의 비트를 읽어 옴
-
레지스터 읽어 오기
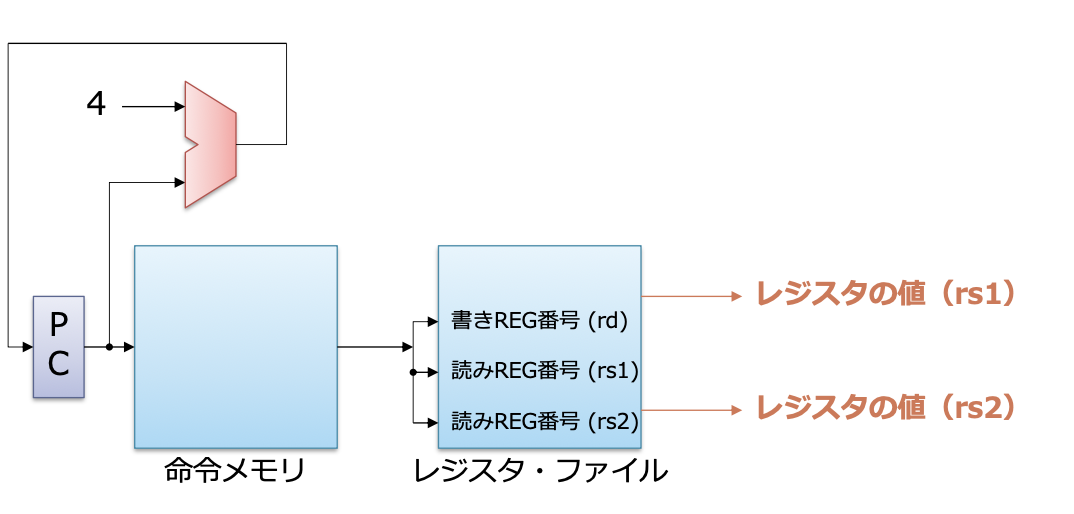
- 디코드로부터 얻은 레지스터 번호를 이용해 RF에 액세스
- 소스, 피연산자의 값을 읽어 옴
- 디코드로부터 얻은 레지스터 번호를 이용해 RF에 액세스
-
실행
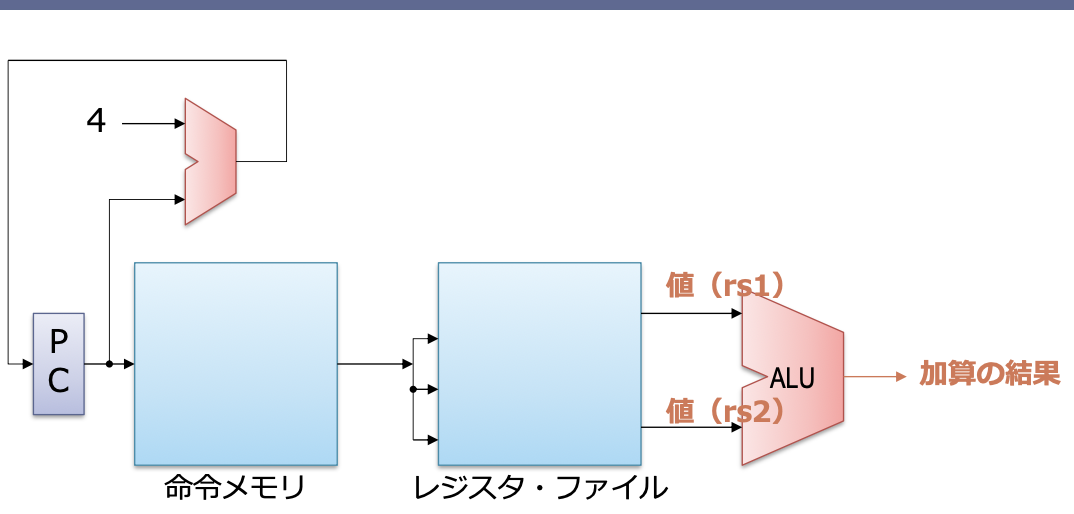
- RF로부터 읽어 온 두 개의 값을 더함
-
레지스터에 써 넣기
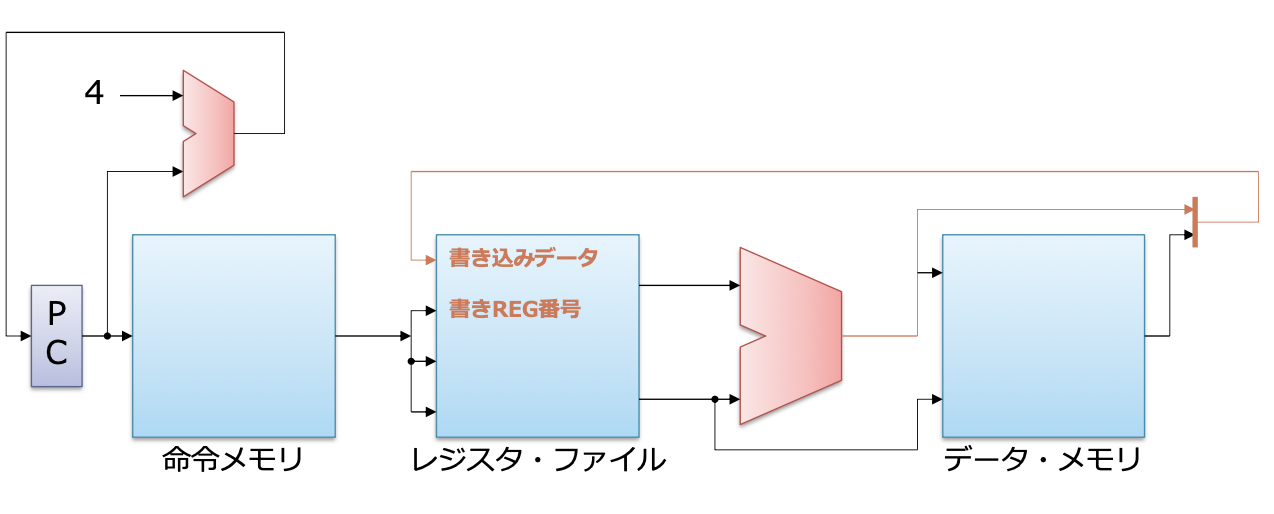
- 덧셈의 결과를 레지스터와 파일에 써 넣음
- 데이터, 메모리에는 아무 작업도 하지 않음
-
- 로딩의 경우: 메모리, 액세스가 변경됨
- 덧셈 명령과의 차이
- 어드레스의 계산
x[rs1] + immediate을 ALU로 처리 - 얻은 어드레스로 데이터와 메모리에 액세스
- 어드레스의 계산
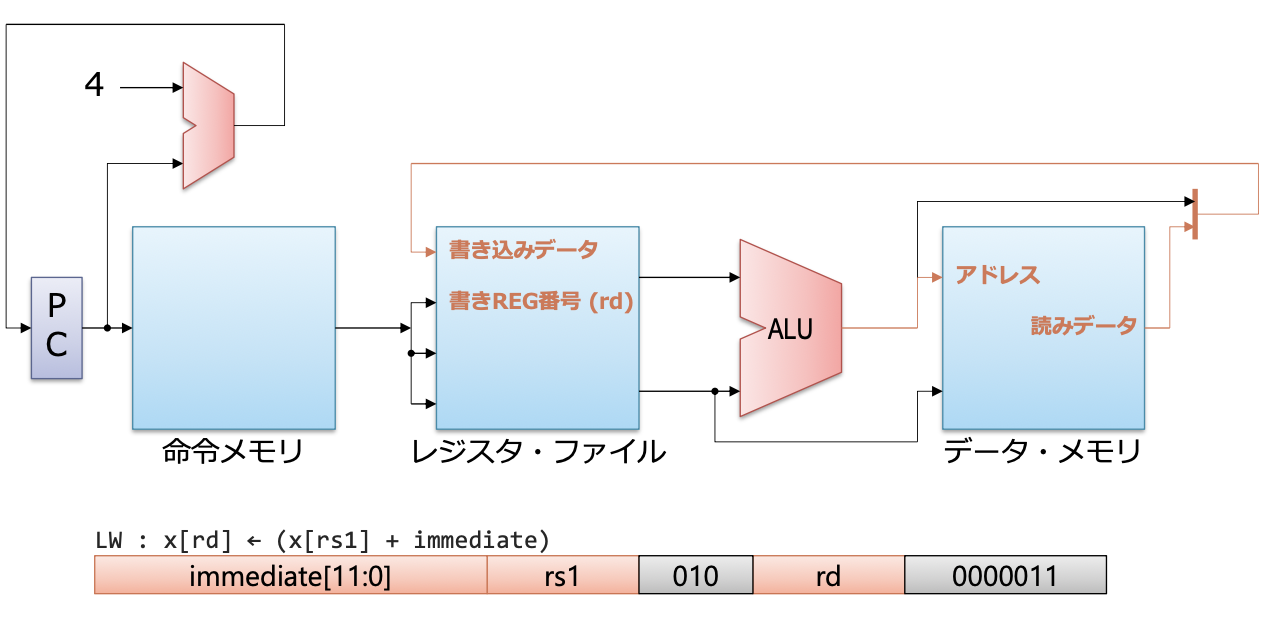
- 덧셈 명령과의 차이
-
각 처리는 기본적으로 왼쪽에서부터 오른쪽으로 흐름
- 특정 유닛에서 작업하고 있을 때, 다른 유닛은 아무것도 하지 않음
- 파이프라인화를 도입해, 처리를 오버랩하여 효율적인 처리가 가능하도록 함
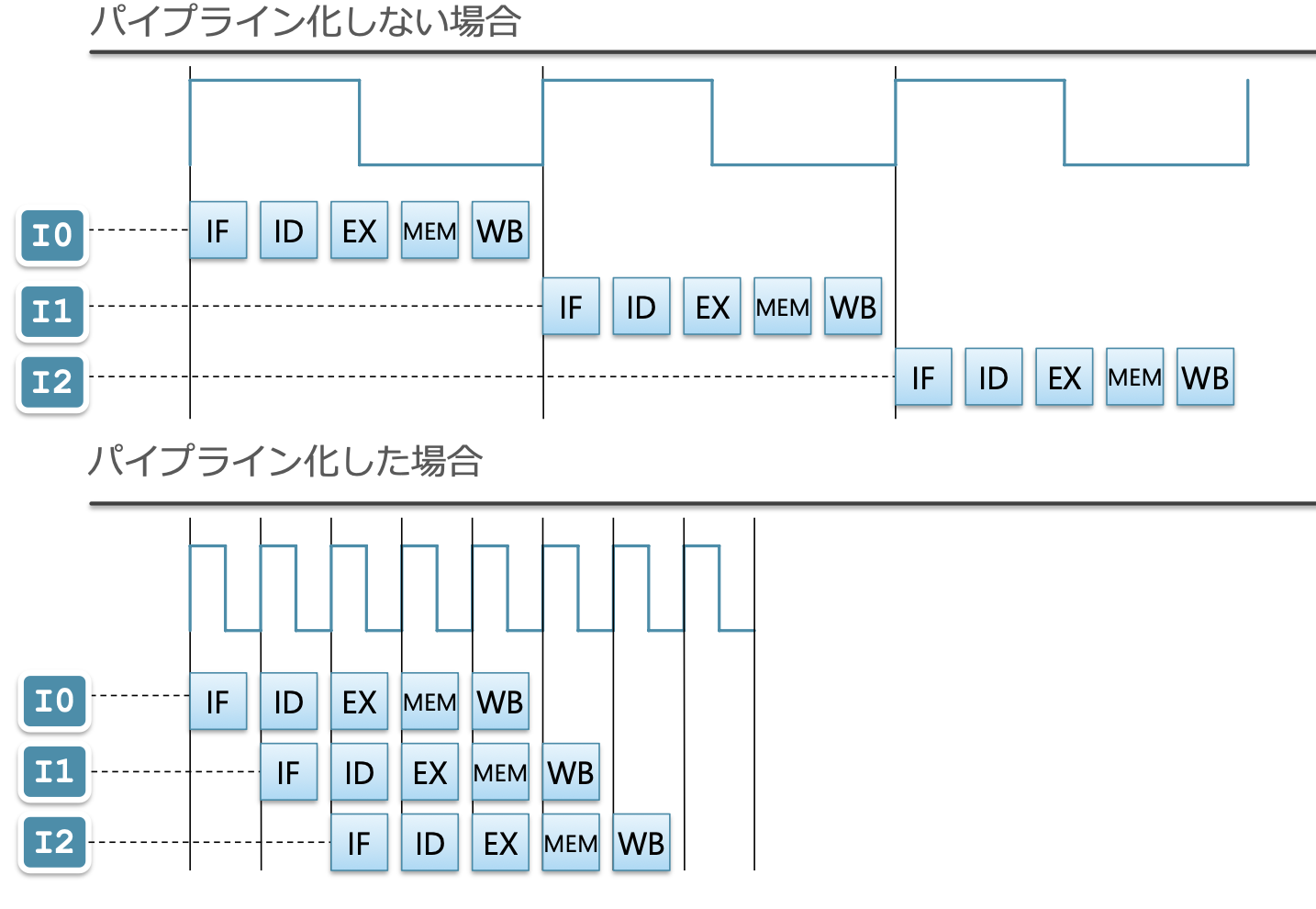
파이프라인화
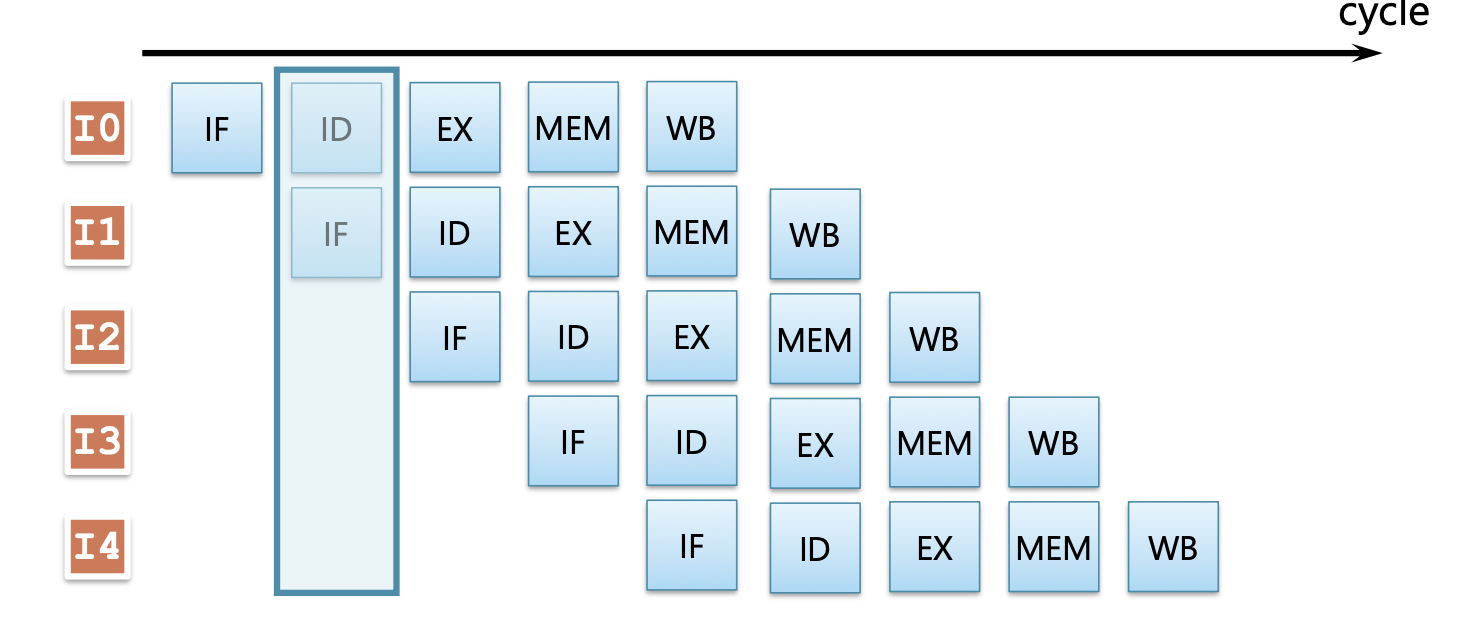
- 읽는 방법
- 시간은 왼쪽에서 오른쪽으로 흐름
- 명령은 위에서 아래로 실행 순서대로 배치됨
- 각 스테이지를 나타내는 사각형은, 해당 시점에 왼쪽에 있는 명령이 그 위치에 존재함을 나타냄
- 위의 예에서는 2사이클째에 I0이 ID에서 처리 중, I1이 IF에서 처리 중임
- 파이프라인화에 따른 성능 향상
스테이지를 어떻게 나눌 것인가?
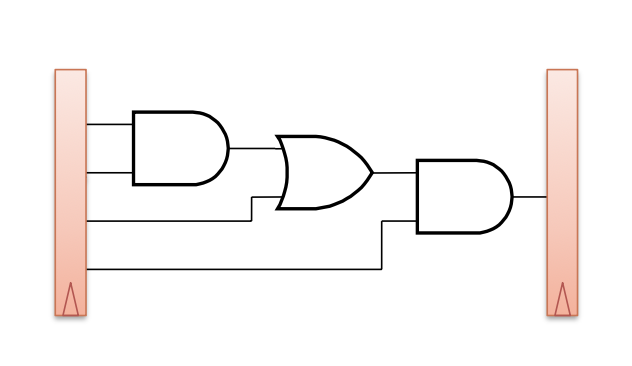
- 싱글 사이클 프로세서의 회로에 명령을 적당한 간격으로 흘려보내기만 하면 된다는 것은 아님
- 각 스테이지를 완전히 동일한 길이로 만드는 것은 매우 어려운 일임
- 동일한 길이 = 동일한 지연 = 완전히 같은 단계 수의 조합 회로 구성
- 스테이지가 길더라도 신호는 끊임없이 변화할 가능성이 있음
- 짧은 경로부터 순서대로 출력에 반영됨
- 예를 들어 아래 회로에서 a, b, c, d가 모두 변할 경우, 먼저 d의 변화가 z에 반영되고, 그다음 d가…
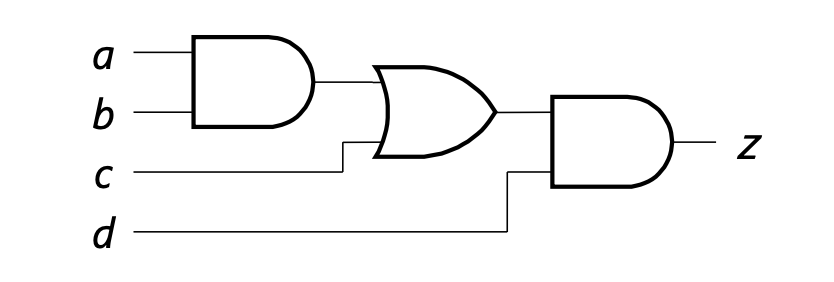
- 각 스테이지를 완전히 동일한 길이로 만드는 것은 매우 어려운 일임
- 파이프라인화(오버랩)의 표현 방법
- 싱글 사이클 프로세서에 플립플롭을 넣는 방식
- 이를 위한 플립플롭을 파이프라인 래치라고 부름
- 래치(latch)는 ‘문이나 대문의 걸쇠’라는 의미를 가짐
- 파이프라인 래치로 나뉜 부분이 스테이지가 됨
- 이를 위한 플립플롭을 파이프라인 래치라고 부름
- 한 사이클 동안은 파이프라인 래치에서 신호가 멈춘 상태를 유지함
- 여러 스테이지 간에 신호가 섞이는 것을 방지함
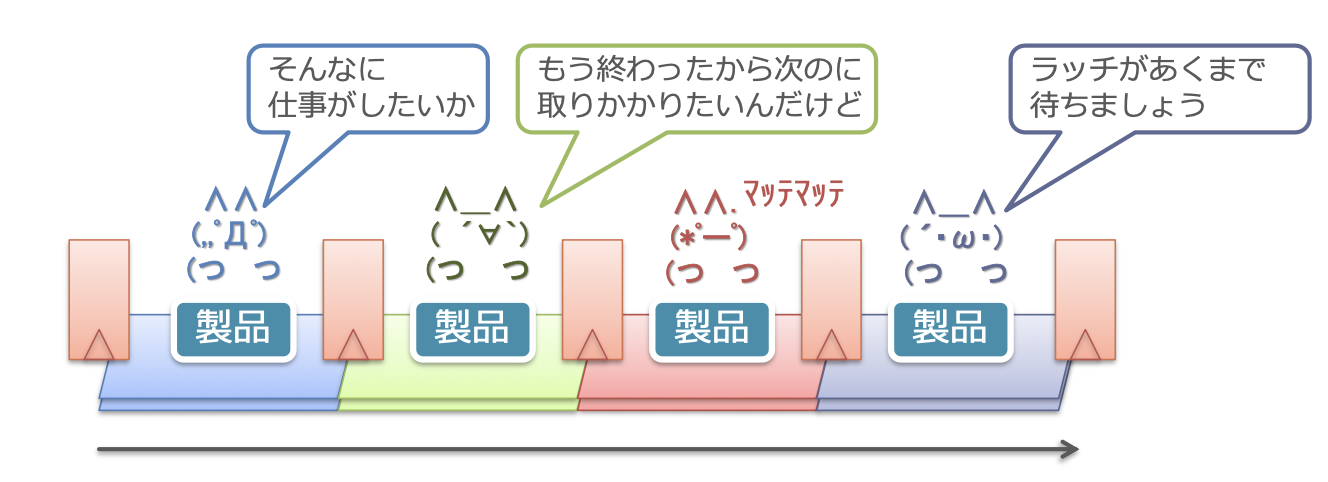
- 지정된 시간까지 래치에서 문을 열지 않게 하는 이미지로 이해할 수 있음
- 각 사람이 작업을 마쳤더라도, 래치가 열릴 때까지는 다음 사람에게 제품을 전달할 수 없음
- 여러 스테이지 간에 신호가 섞이는 것을 방지함
- 지정된 시간까지 래치에서 문을 열지 않게 하는 이미지로 이해할 수 있음
- 아래 그림에서는 빨간 사람이 아직 작업을 끝내지 않았기 때문에, 전체가 보조를 맞추기 위해 기다리고 있는 상태임
- 싱글 사이클 프로세서에 플립플롭을 넣는 방식
- 각 스테이지 사이에 D-FF(주황색 사각형)을 넣는 방식
- WB의 쓰기에 대해서는, 레지스터 파일 자체가 클록에 맞춰 쓰기가 이루어지므로 D-FF는 불필요함
- 각 스테이지의 처리가 빨리 끝나더라도, 다음 클록까지는 D-FF로 신호 전달을 멈추는 방식임
- 레이턴시 latency
- 하나의 연속된 처리가 시작되어 끝날 때까지 걸리는 시간
- 이 경우, 하나의 명령어가 시작되어 종료될 때까지의 처리 시간
- 가장 오래 걸리는 처리 시간에 맞춰 동작하므로 시간이 늘어남
- 원리적으로 짧아지지 않음(혹은 오히려 약간 늘어남)
- 스테이지 사이에 플립플롭이 들어가는 만큼은 무조건 늘어남
- 하나의 연속된 처리가 시작되어 끝날 때까지 걸리는 시간
- 처리량(스루풋 throughput)
- 스테이지 수만큼 증가함
- 단위 시간당 처리량
- 이 경우, 단위 시간당 실행되는 명령어 수
- 그래서 어디서 나눌 것인가?
- 큰 회로 단위를 스테이지로 구성하는 방식
- 회로 단위가 클수록 -> 지연도 커지는 경향이 있음
- 이러한 지연의 크기가 일정하지 않으면, 제대로 동작하지 않음
- 파이프라인 전체는 가장 느린 스테이지의 지연에 맞춰 동작함
- 다른 사람이 작업을 끝냈더라도, 먼저 보낼 수 없음
-
좋지 않은 예시: 초록색 사람만 일이 많아서, 전체가 움직일 수 없는 상태가 됨
- 스테이지
- IF: 명령어 페치
- ID: 디코드와 레지스터 읽기
- EX: 실행
- MEM: 메모리 접근
- WB: 레지스터 쓰기
- 위에서는 디코드와 레지스터 읽기를 ID 스테이지에 통합한 형태임
- 디코드에 걸리는 지연은 거의 없음
- 읽어들인 명령어에서 오퍼랜드를 꺼내는 것은 단순히 신호선을 연결하는 것으로 가능함
- 큰 회로 단위를 스테이지로 구성하는 방식
파이프라인화의 성능에 대한 영향
- 파이프라인화의 효과
- 처리량의 향상
- = 단위 시간당 처리할 수 있는 명령어 수의 증가
- = 동작 클럭 주파수의 향상
- 위 내용들은 같은 말을 다르게 표현한 것에 불과함
- 처리량의 향상
- 스테이지 내 신호 전파 고려하기
- 파이프라인: 스테이지:
- 여러 개의 파이프라인 래치 사이에 끼워져 있는 조합 회로(게이트)
- 화살표의 움직임
- 클록이 시작될 떄, 왼쪽 래치에서 나온 신호가 조합 회로를 거쳐 전파되어 가는 모습
- 파이프라인: 스테이지:
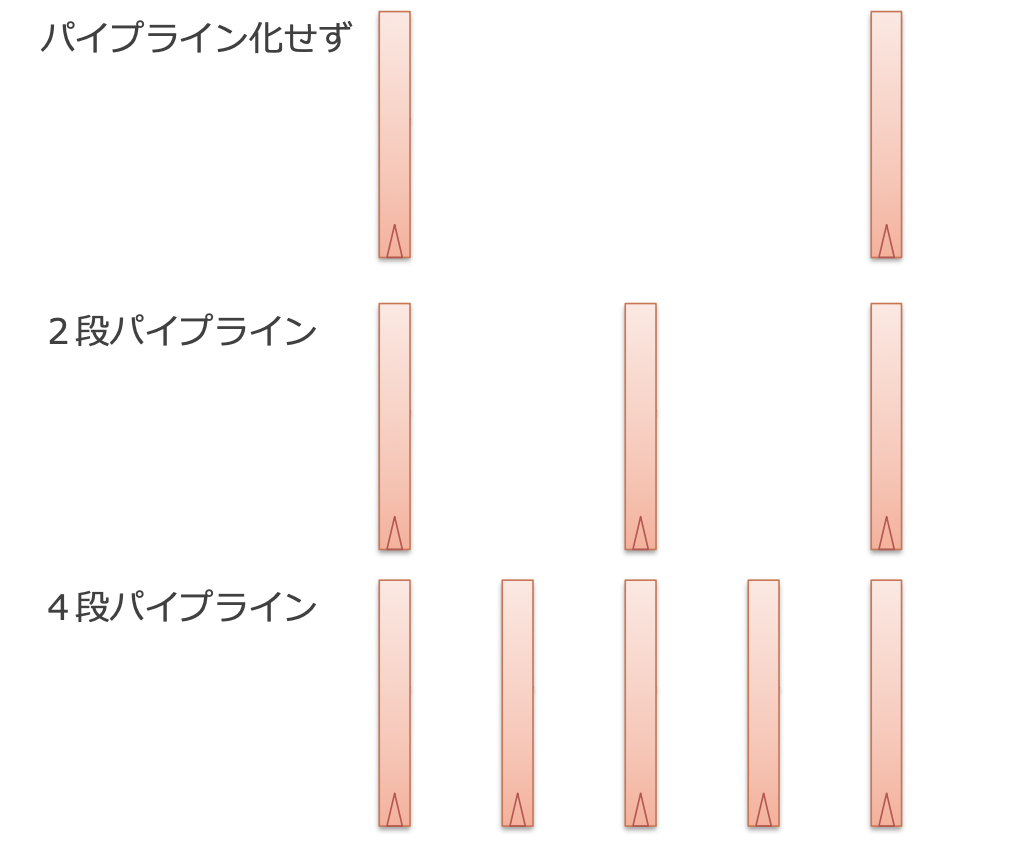
- n단 파이프라인화했을 경우
- 2단으로 파이프라인화
- 블록 주파수가 2배가 됨
- 각 화살표가 뻗어가는 속도(신호가 전파되는 속도) 자체는 동일
- 2단 파이프라인에서는, 래치로부터 신호가 두 번 출력됨
- 4단으로 파이프라인화
- 블록이 주파수가 4배
- 4배 파이프라인에서는, 래치로부터 신호가 4번 출력됨
- 2단으로 파이프라인화
- 파이프라인화의 한계
- 파이프라인 단수를 계속 늘린다고 해도, 무한히 빨라지지 않음
- 이유
- 회로적인 이유로 인한 주파수 향상의 한계
- D-FF 자체의 지연
- 소비 전력과 발열
- 아키텍처적인 이유로 인한 실효 성능의 한계
- 회로적인 이유로 인한 주파수 향상의 한계
- (발전) 이유 1: D-FF 자체의 지연
- 기억소자의 원리
- 2개의 NOT 게이트를 루프시킨 회로로 구현
- 두 가지 안정 상태가 존재, 이 둘 중 어떤 상태에 있는지에 따라 1비트의 정보를 기억함
- D 래치의 회로
- 멀티플렉서가 포함된 인버터(NOT 게이트)의 루프
- 멀티플렉서를 전환 스위치로 설명
- 클록의 상승 엣지마다 스위치가 전환됨
- d의 값을 루프에 받아들이고, 받아들인 값이 q로 출력됨
- D-FF의 회로
- 구조: D 래치를 2개 연결한 구조
- D 래치 하나만으로는, 반 주기 동안 d에 입력된 값이 반영되어 그대로 통과되기 때문에 사용하기 편함
- 따라서 2개를 직렬 연결해 해당 통과 구간을 없앰
- 클록의 상승 엣지마다 d의 값이 샘플링됨
- 해당 값이 다음 클록 사이클 동안 q에서 출력됨
- 구조: D 래치를 2개 연결한 구조
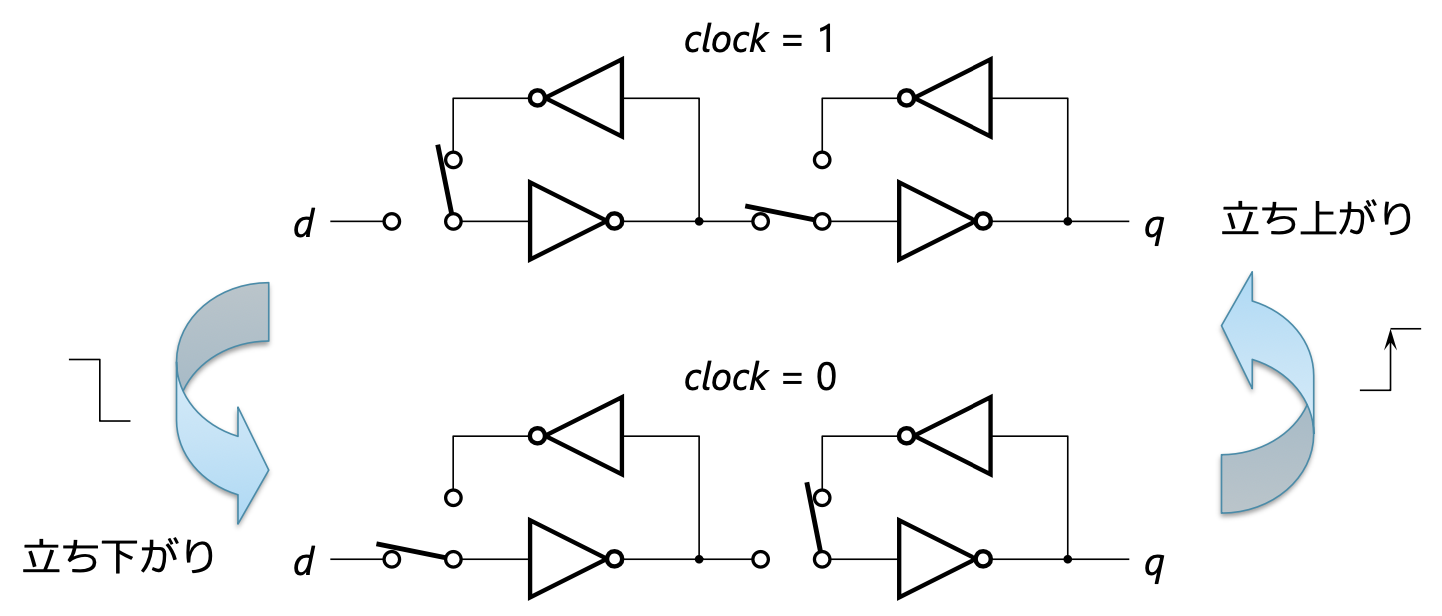
- D-FF의 동작
-
블록 신호가 Low
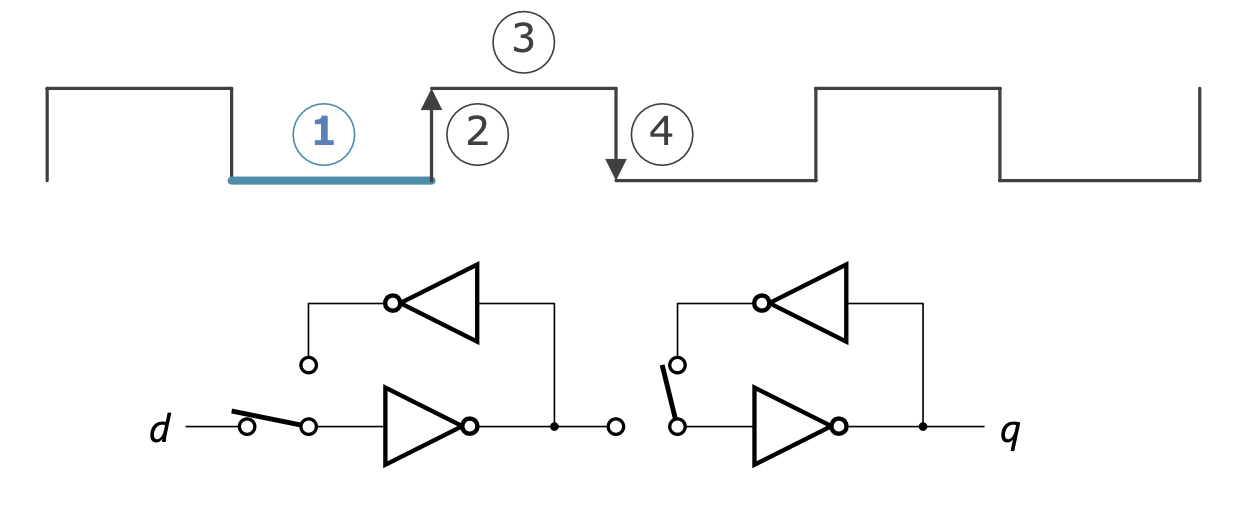
- 왼쪽 루프
- d 입력의 변화에 따라 인버터의 상태가 수시로 전환됨
- 오른쪽 루프와는 차단되어 있음
- 오른쪽 루프
- 루프 내 인버터의 상태(= 기억된 값)가 q로 계속 출력됨
- 왼쪽 루프
-
블록 신호의 상승
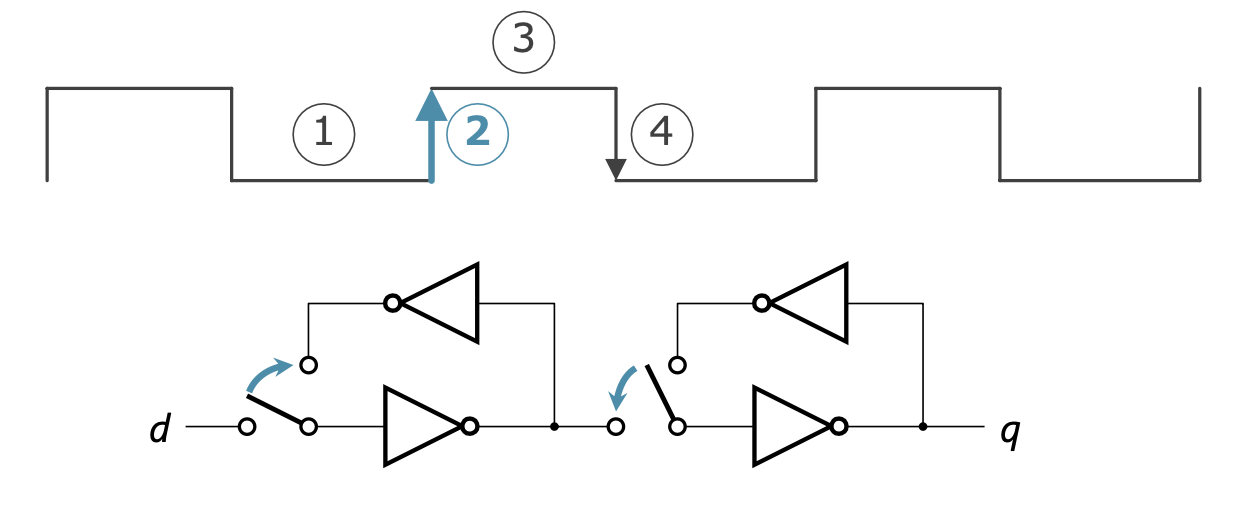
- 왼쪽 루프
- d와 차단되어 루프가 형성됨
- 직전까지 d에 입력되어 있던 신호가 기억됨
- 오른쪽 루프
- 왼쪽 루프와 연결되어 루프가 해제됨
- 왼쪽 루프
-
블록 신호가 High
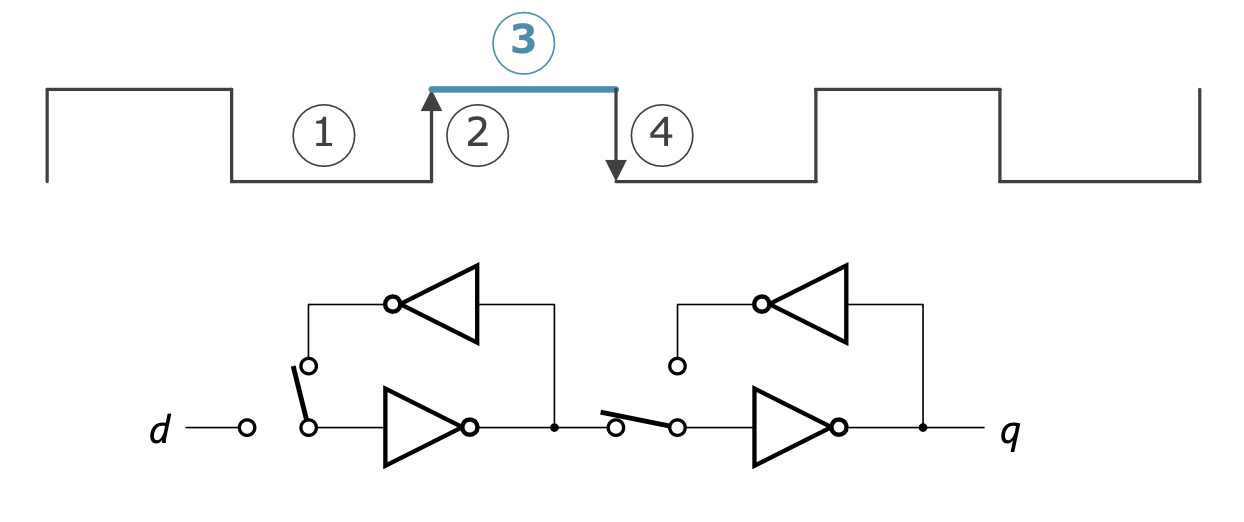
- 왼쪽 루프
- 클록이 상승하기 직전의 d 값을 계속 출력함
- 오른쪽 루프
- 왼쪽 루프의 출력을 반전시켜 q로 출력함
- 왼쪽 루프
-
블록 신호가 하강
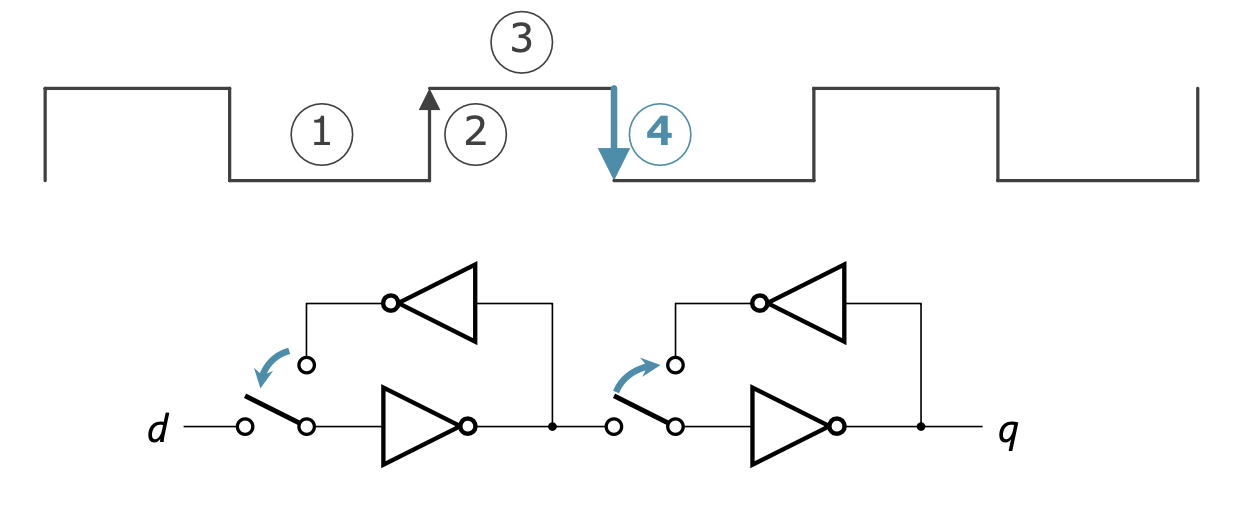
- 왼쪽 루프
- 루프가 해제됨
- 오른쪽 루프
- 왼쪽 루프와 차단되어 루프가 형성됨
- 그동안 왼쪽에서 입력된 내용을 계속 출력함
- 왼쪽 루프
-
- D-FF의 지연
- 위의 4단계 동작에 따른 지연
- 스위치가 전환될 떄까지의 지연
- 스위치가 전환된 후, 인버터 입력에 따라 출력이 변할 때까지의 지연
- 클록 주파수를 지나치게 높이면 이러한 한계에 부딪히게 됨
- 한 스테이지 내 조합 논리 회로의 지연: 인버터로 환산하면 보통 10~20단 정도
- 따라서 D-FF 자체의 지연도 무시할 수 없을 정도로 큼
- 위의 4단계 동작에 따른 지연
- 기억소자의 원리
- 이유 2: 소비 전력과 발열
- 클록 주파수를 높이면
- 단위 시간당 회로 전체의 충전/방전 횟수가 증가
- 소비 전력과 그에 따라 발생하는 열도 그만큼 증가함
- 전력 공급의 한계
- CPU 칩의 단자에서 흘려보낼 수 있는 전류에 한계가 있음
- 오옴의 법칙: V = IR
- 단자의 핀 수에 따라 저항 R이 결정됨
- 방열의 한계
- 온도가 상승할 때, 방열 속도가 그 증가를 따라가지 못함
- 클록 주파수를 높이면